之前看过一泽老师写的一篇测评,
说的是大模型读不懂「疯狂星期四」。

原文在此: https://mp.weixin.qq.com/s/Gb03tcT-NHvbKP4mJ7CODg
当然,文章里的“疯狂星期四”,
不是大家平时所理解的那样。
那篇文章里,
他给那些有名的模型测了很多道猜谜游戏,
进行了个排名。
发现当前的大模型做较难的猜谜题相对偏弱。
比如,那道著名的“疯狂星期四”。

没有模型答对。
然后昨天,
我正好在刷x,
刷到了一篇和这个思路异曲同工的论文。

还真的有研究者们在研究这方面的问题。
他们构造了特意构造了一个看图猜谜的评测集,
来说明当前的模型在做这种偏难的看图猜谜的时候普遍偏弱。
比如,下面这个题,
你也可以猜猜答案是什么:

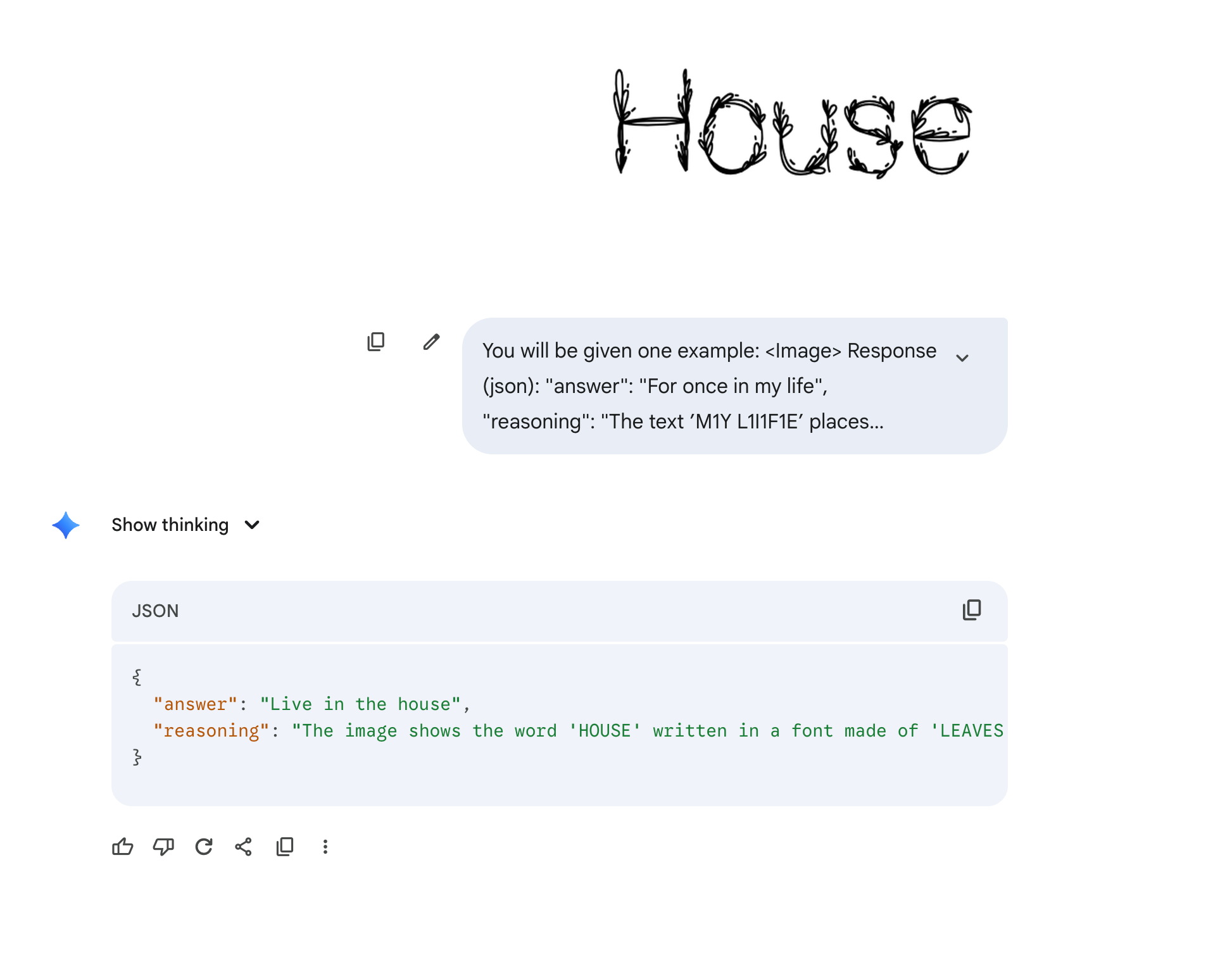
我直接问GPT-5 Thinking 这是啥单词。
它只能回答出是House。

ber, 大哥你回答的倒是真挺快的。
要这么简单,我还问你干嘛。
我又去问了封号斗罗,claude。

一样的回答,也没回答上来。
后来,我一寻思,

是我问的方式不对。
于是我用了论文里的提示词,来试试。
比如,下面这个包含着上下文的提示词。

虽然也没答对,但是总体效果上好点。

下面这个是Gemini 2.5 Pro 的:
推理得还挺像模像样的。
好了,现在可以公布答案,是
“HousePlant"。
不知道正在看篇文章的你有没有猜出正确答案,
但反正我,是回答不出来。

这篇论文的几个作者,
构建了400多道像这样的看图猜谜题给几个主流的大模型,
测下来,效果感人。。。
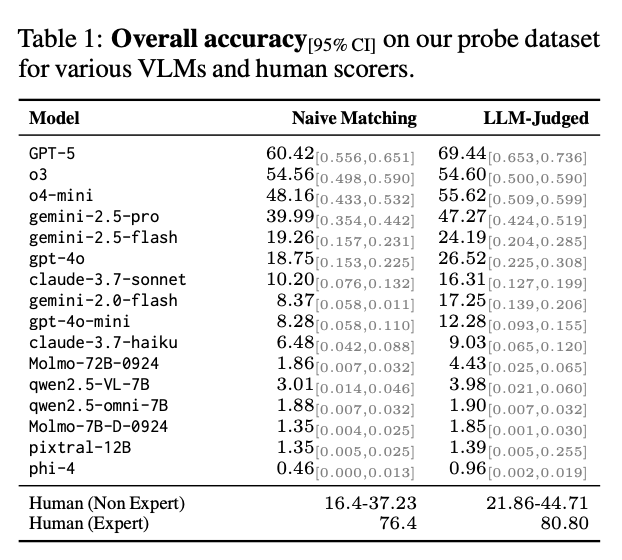
他们分了两种评测方式,
一种是最简单的朴素评估,就是看模型回答的答案是否和标准答案完全一致,
还有一种是LLM做评委,从语义上来判断模型的答案是否和标准答案是一样的。
从结果可以看到,
表现比较好的还是闭源的那几个模型,效果都还不错,
已经远超人类非专家的表现了,
特别是GPT-5,
真有两下子看来。
但是除了GPT-5 勉强算及格了以外,
其他模型效果都巨差无比。
所以如果你是玩这类游戏的高手,
不用太担心,
AI 还暂时玩不过你。

但是,为什么呢?
咱就是说,
是什么原因让AI对这类题目表现都不咋地呢?
这些研究者们做了一定的分析,
一个是,这类看图猜谜题的本质,
要求无论是人也好,模型也罢,都要有很高的抽象以及横向推理的能力。
也就是说,
你不能只看表面,还要看背后的实质。
这就有点像,
领导表面是关心,
问最近工作怎么样,
实际上想说的是,
你最近工作真的不怎么样。

这种高度的抽象、推理能力的缺失,也正是当前模型存在的根本性缺陷。
还有就是,
模型对于一些视觉隐含的意义以及对人类约定俗成的文化梗的理解还是存在问题。
比如,

这个water弯曲的样子,
其实隐喻的是瀑布。
这就和模型的训练方式有关。
大部分的模型的训练数据,
都是图像与文字直接对齐,导致并没有在这方面做过多的训练。
还有一个原因是,
模型通常能识别一张图里有什么,
但是模型对于识别一张图里没有什么,相对来说就比较欠缺。
比如下面这个图,

猜猜答案是什么。。。
这个应该比较简单,
就是long time no see.
封号斗罗和GPT-5 Thinking都回答对了。
但是我换一个稍微难一点的图,

再猜猜答案是什么?
Claude 一通瞎答,

不知道是咋理解的图,反正是回答错误。
现在公布答案,
是“miss u" 。
谜题背后,是人类独有的、基于生活经验和文化背景的联想、抽象和共识。
我们能理解疯狂星期四背后的戏虐,
能看懂water和waterfall的联系,
能体会HousePlant 组合的巧妙,
也能感知到miss u 那份直白的缺失。
这并非是说AI永远无法理解。
技术的迭代日新月异,或许几个月后,新的模型就能轻松答对这些题。
但这整个过程,我们出题、AI答题、AI答错、我们分析它为何答错的意义,已经超出了评测本身。
它更像是一个反向定义的过程。
在试图教会机器如何像人一样思考时,
我们也一次次被提醒:
究竟是什么,构成了我们的思维深度。
也许,这才是疯狂星期四们,对我们最大的价值。
以上,
若觉得内容有帮助,欢迎点赞、推荐、关注。别错过更新,给公众号加个星标⭐️吧!期待与您的下次相遇~