I read a review by teacher Yi Ze about large models failing to understand “Crazy Thursday”.

Original: https://mp.weixin.qq.com/s/Gb03tcT-NHvbKP4mJ7CODg
The Crazy Thursday in that article is not the usual meaning. The author tested many famous models on riddle games and ranked them.
The conclusion was that large models are weak at harder riddles, like the famous Crazy Thursday.

No model got it right.
Yesterday I saw a paper with a similar idea while browsing X.

Researchers built a visual riddle benchmark to show that current models are weak at this type of puzzle.
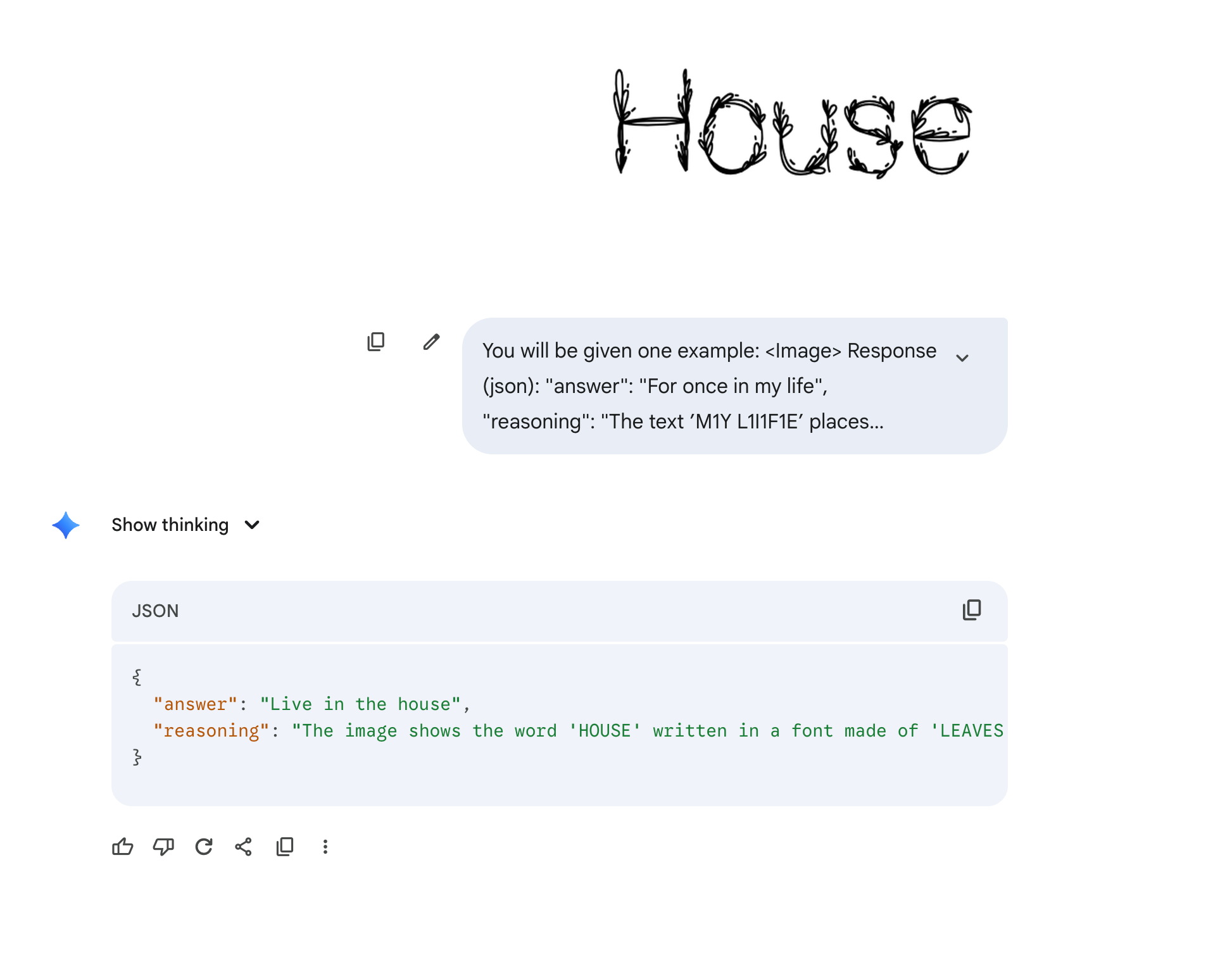
Here is an example. Try to guess the answer.

I asked GPT-5 Thinking for the word. It only answered House.

That was fast, but too simple. I asked a model that often gets accounts banned, Claude.

Same answer, still wrong.
Then I realized the prompt might be wrong.

I used the paper prompt with context.

Still wrong, but the reasoning improved.

Here is Gemini 2.5 Pro:
The reasoning looks decent.
Now the answer is “HousePlant”.
I could not get it.

The authors built 400+ visual riddles and tested major models. The results were rough.
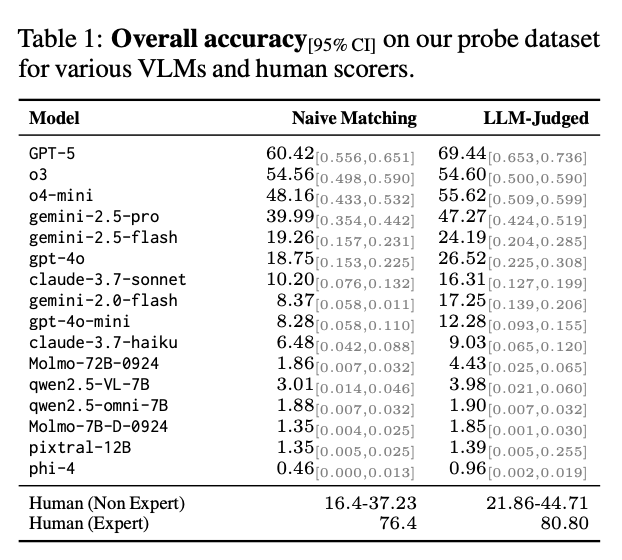
They used two evaluation styles:
One is strict exact match. The other uses an LLM judge to check semantic equivalence.
Closed models still perform better and already beat non expert humans. GPT-5 is strong.
But aside from GPT-5 barely passing, other models were very weak.
So if you are good at riddles, do not worry. AI still cannot beat you.

But why
The authors argue these riddles require strong abstraction and lateral reasoning. You cannot just look at the surface, you have to see the meaning beneath.
That is like a manager saying they care about your work, when they actually mean you are underperforming.

This lack of abstract reasoning is a core weakness of current models.
Another reason is that models struggle with implied meanings and cultural conventions.
For example:

The curved water hints at a waterfall. This is tied to training data. Most models align images with captions and do not train on such metaphors.
Another reason is that models can detect what is present in an image, but struggle to detect what is absent.
For example:

Guess the answer. This one is easier. It is “long time no see”. Both Claude and GPT-5 Thinking got it.
Now a harder one:

Claude guessed wrong.

The answer is “miss u”.